数据结构基础(C语言实现)—— 变长数组
仿照 Java 的 ArrayList 实现的可变长数组,可惜的是 C 语言没有像 Java 中那么灵活方便使用的泛型,需要使用无类型指针 (void *) 实现,这里只是做个笔记,就不搞的太复杂了。
容量变化规则同之前实现的顺序栈一样(PS:顺序栈的代码大部分是从这里拷贝过去的),这里再说明一下:
扩容规则是栈满则扩大一倍;
缩容规则是当前数量为容量的 1/4 时,容量缩小到当前的一半,之所以要到 1/4 的时候再缩容而不是到 1/2 就缩容,是为了防止数量刚到 1/2 时又立刻压入栈元素导致扩容;
数组结构体
1234567891011121314//// Created by Tianyi on 2021/10/26.//#ifndef UNTITLED_STRUCT_H#define UNTITLED_STRUCT_H#endif //UNTITLED_STRUCT_Hstruct MineArrayList { int count; int capacity; int *arr;};
变长数组相关操作
1234567891 ...
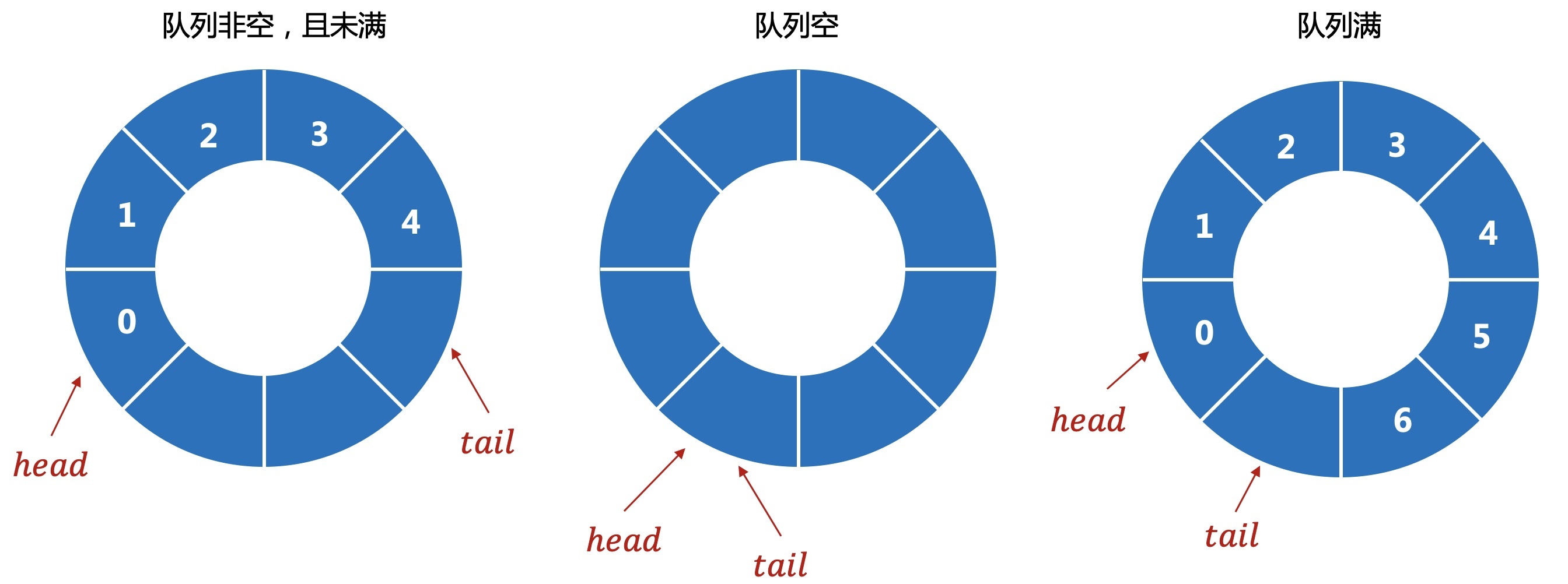
数据结构基础(C++语言实现)—— 循环队列
这是使用数组实现的循环队列,同样也可以用链表实现,但原理都是一样的,就不重新写一份了,简单实现了数据的取出插入
类定义
12345678910111213141516171819202122232425262728293031//// Created by Tianyi on 2022/1/6.//#ifndef DATA_STRUCT_CIRCULAR_QUEUE_CIRCULAR_QUEUE_H#define DATA_STRUCT_CIRCULAR_QUEUE_CIRCULAR_QUEUE_H#include <iostream>using namespace std;#endif //DATA_STRUCT_CIRCULAR_QUEUE_CIRCULAR_QUEUE_Hclass CircularQueue {private: int * data; int capacity; int count; int head; int tail;public: explicit CircularQueue(int capaci ...
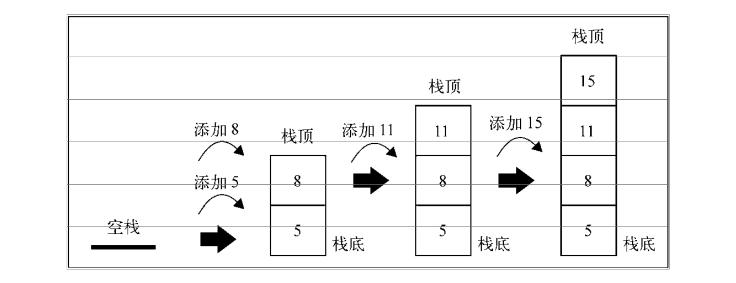
数据结构基础(C语言实现)—— 顺序栈
这个是使用数组实现的顺序栈,可以实现扩容和缩容,链表栈原理一样,上一篇链表中也实现了相关的函数,直接调用即可完成栈操作,就不重复写了。
扩容规则是栈满则扩大一倍;
缩容规则是当前数量为容量的 1/4 时,容量缩小到当前的一半,之所以要到 1/4 的时候再缩容而不是到 1/2 就缩容,是为了防止数量刚到 1/2 时又立刻压入栈元素导致扩容,缩容后立即扩容会有以下两个问题:
效率低下,申请资源和释放资源都都需要时间,这个问题可以使用链表解决,但这里仅讨论顺序表实现的顺序栈;
因为是顺序栈,万一资源紧张,当释放掉一半的资源后立即申请两倍的资源,是有可能申请不到的,这个也可以用链表栈解决;
相关结构体定义
1234567891011121314//// Created by Tianyi on 2021/11/2.//#ifndef DATA_STRUCT_ARRAYSTACK_STRUCT_H#define DATA_STRUCT_ARRAYSTACK_STRUCT_H#endif //DATA_STRUCT_ARRAYSTACK_STRUCT_Hstruct ArrayStack & ...
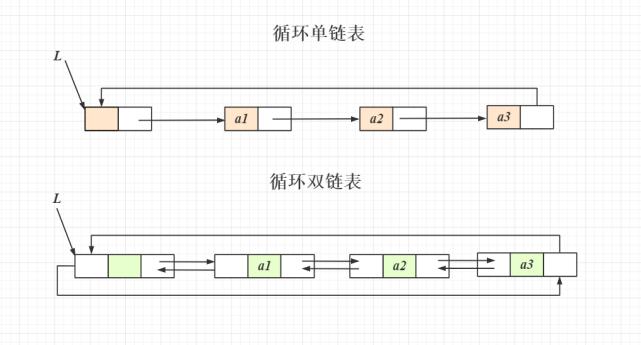
数据结构基础(C语言实现)—— 单向链表
最近在看 C 语言,不得不感慨现在的编程语言真的简化了很多操作,更加方便使用,被简化了的东西都被 C 和 C++ 干完了,从客观角度来看,C/C++ 仍然是目前最牛逼的编程语言。
数据结构基础的博客我只是贴个代码,并不写任何相关的知识点。知乎,CSDN,简书,B站,YouTube,Stack Overflow 这些网站上多的是比我这个半瓶水的要说得明白得多的博客和帖子,我只是基于我自己的理解写出来的代码,如果有疑问或者代码错误可以在评论提出,谢谢。
链表节点和链表结构体
12345678910111213141516171819202122232425262728//// Created by Tianyi on 2021/10/28.//#ifndef DATA_STRUCT_LINKLIST_STRUCT_H#define DATA_STRUCT_LINKLIST_STRUCT_H#endif //DATA_STRUCT_LINKLIST_STRUCT_H/** * 链表节点结构体 */struct LinkNode { int value; struct ...
JVM 中类的加载(二)
温故而知新,可以为师矣
前不久又复习了一下 JVM 的类加载机制,并对上一篇类加载的博客进行了部分修正,也添加了部分知识点,第二篇也是对第一篇类加载机制博客的延伸,总结与实践;
上篇类加载机制博客指路地址:JVM 中类的加载
延伸
Klass 模型
Java 在 JVM 中的内存形式
Java 类在 C++ 的类 Klass
Klass 又可以分为两类:
非数组类
InstanceKlass
这是普通的类在 C++ 源码中的体现形式,类的元信息在 JVM 中对应的就是 InstanceKlass,存在于方法区中,用于存储该类的访问权限,方法信息等。
InstanceMirrorKlass
这是类的实例在 C++ 源码中的体现形式,存在于堆区,类的静态属性也是存储在 MirrorKlass 中的,处于运行时内存中的。
数组类
基本数据类型
boolean
char
byte
short
int
long
float
double
以上的基础类型对应的是 TypeArrayKlass
引用数据类型
对应的是 ObjArrayKlass
...
BW 一年一记 No.1
这周周末真的太开心了,有好多开心的事,已经很久很久没有这么开心过了,好难得,必须要记录一下。
Bilibili 是我从大二开始就一直使用的视频平台,从刚开始用来追番的工具,变成现在学习和生活中必不可少的 App,B站这个平台带给我很多快乐,知识,已经成为了我每天必刷的视频平台。
关于 Bilibili World,我很早就开始关注了,但是一直没什么兴趣,因为当时我对二次元文化并没有太多了解,但是从19年我开始追各种动漫后,对这个圈子逐渐了解,从去年开始玩原神后,就愈加变得一发不可收拾了(其实今年去 BW,很大程度是因为原神今年也参加了 BW,我也是冲着这个去的)
5:30 起床赶场子
凌晨五点迷迷糊糊爬起来,打开聊天群就已经看到有人已经出发了,我当时还说我5点半起床洗漱完后,至少6点就能到地铁,然而,我实在太困了,起不来啊,就耽搁了半个小时,最后6点半出的门,打了个车到地铁站。
一个半小时的地铁。。。。
在2号线上看到了去参加 BW 的 cos,是原神的胡桃,人太多了,没好意思要拍照。。。。。。
8点开始漫长的排队
说到这个,我真的好绝望,绝望到我发誓明年的 BW 我一定要 ...
Python-Sqlparse API 笔记
sqlparse.split(sql, encoding=None)
12345678def split(sql, encoding=None): """ 将一个由多条 SQL 拼接的字符串切分成多条 SQL :param sql: 包含一个或多个 SQL 语句的字符串 :param encoding: SQL 的字符集 :returns: 返回一个包含被切分好的 SQL 语句 List """
sqlparse.format(sql, encoding=None, **options)
12345678def format(sql, encoding=None, **options): """ 根据 option 配置调整 sql 格式 除了格式化选项之外,该函数还通过 encoding 配置决定了语句的编码。 :returns: 返回一个格式化完成的 SQL """
keywo ...
Python Hexo Valine 评论回复邮件通知工具
项目地址
hexo-blog-tools
项目介绍
去年年底,我重新把自己多年不用的静态博客重新搭建起来了,这次换用了 Butterfly 主题,用阿里云 OSS 对象存储进行搭建,评论系统还是使用的 Valine,但是搭建完成后,就发现个大问题,Valine 官方不支持邮件回复了!!!!
这就很难受了,随即我又看到官方说可以使用第三方的邮件插件 Valine-Admin
兴奋的我打开了 Valine-Admin 官网,琳琅满目的配置实在是让我感觉到很难受,而且,Valine-Admin 使用方法中,使用的部署方法在 LeanCloud 更新后好像找不到了,折腾了一天无果后,我放弃了使用这个插件了,可是不用这个插件我就没法收到邮件通知了啊,那咋办呢?重写一个 Valine 插件?问题是我不会 JavaScript 啊,就算是能写出来,还要集成到 Hexo 中,这就严重涉及到知识盲区了。
带着一咩咩希望,我打开了 LeanCloud 的控制台,看到了存储评论的表,然后突然灵光乍现,这不是数据表吗?既然是数据表,那不就可以 CRUD 了吗?那问题不久迎刃而解了吗?哈哈哈哈哈哈哈, ...
Spark 配置速查
Spark CPU 相关配置
CPU 个数配置
spark.cores.max: 从集群粒度配置 CPU 个数;
spark.executor.cores: 从 Executor 粒度配置 CPU 个数;
spark.task.cpus: 从计算任务配置 CPU 个数;
并行度配置
spark.default.parallelism: 对于没有明确分区规则的 RDD 设置 Spark 任务的默认并行度;
spark.sql.shuffle.partitions: 明确指定数据关联或聚合操作中 Reduce 端的分区数量;
Spark 内存相关配置
堆外内存
spark.memory.offHeap.enabled: 是否开启堆外内存(true/false)
spark.memory.offHeap.size: 堆外内存大小
堆内内存
spark.memory.fraction: 堆内内存中,用于缓存 RDD 和执行计算的内存比例,这个值在 Spark 2.0+ 为 60%,Spark 1.6 为 75%;
spark.memory.storageFractio ...
MySQL Redo Log 与 BinLog
Redo Log
这个日志可以提高数据库的性能,是 InnoDB 引擎特有的日志,用于记录物理日志,比如数据页上做了什么修改,以及保存事务的提交过程;
该日志文件大小固定,文件写完就会从头开始覆盖,既然会覆盖,那就说明这个日志是不能用于回滚的;
若数据库重启,或者因为异常宕机重启后,Redo Log 可以保证之前提交的事务不会丢失,这种能力叫做 crash-safe ;
BinLog
这个日志是 MySQL Server 的日志,也就是说所有数据库引擎都可以使用这种日志,记录的是数据库的所有增删查改操作;
日志文件是追加模式写入的,并没有大小限制,不会覆盖之前的数据,可以用于恢复数据库中的数据;
如果数据库出现误删或者需要恢复数据库到某一时刻,那就需要该日志中的记录进行恢复;
日志写入过程
当一条数据库操作命令进入 MySQL Server 和存储引擎时,会执行以下几个操作(用更新命令进行解释):
123UPDATE TableSET field1 = valueWHERE field2 = value2
执行器会先去缓存中寻找符合条件的数据,如果缓存中没有找到,就去存储引擎中 ...