JVM 中 Java 代码如何执行
JVM 运行 Java 字节码
从 JVM 来看,执行 Java 程序需要将编译后的 class 文件加载到虚拟机中,加载完成后,Java 类会被放到方法区中,运行时,JVM 就会执行方法区中的代码。
JVM 在内存中划分出堆和栈来保存运行时产生的数据,JVM 在划分栈时,会细分为面向 JAVA 的方法栈和面向本地的本地方法栈(用 C++ 写的 native 方法)。
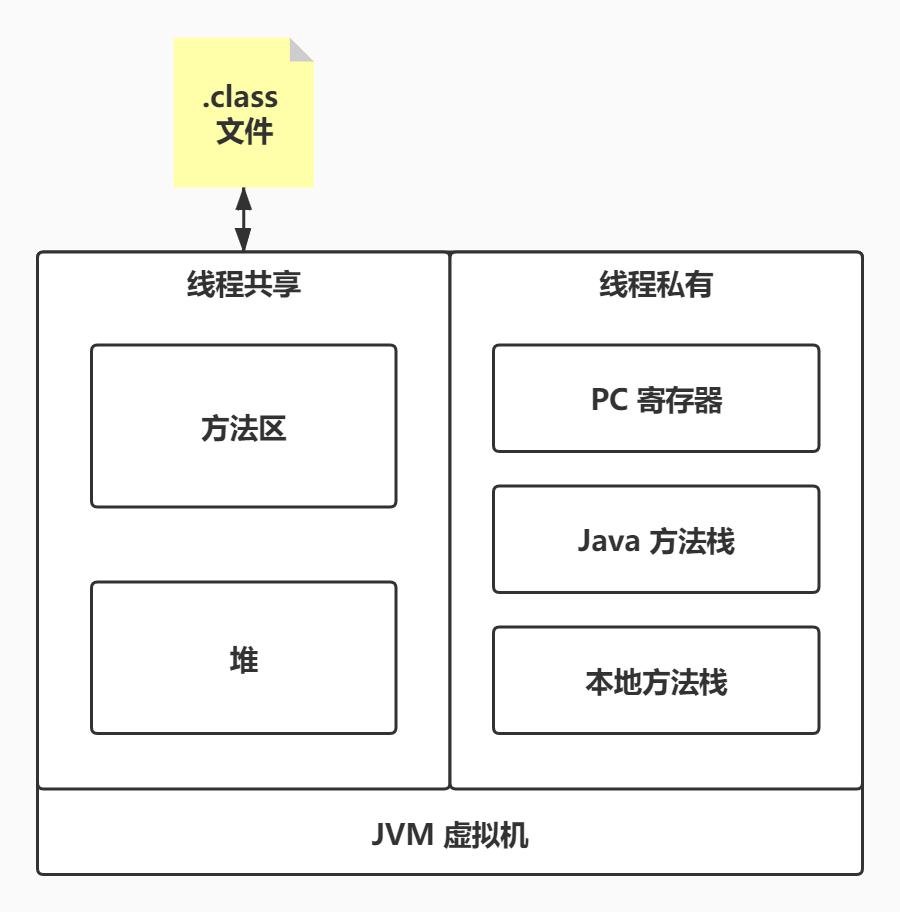
当调用一个方法时,JVM 会在 Java 方法栈中生成一个栈帧用于存放方法的运行时数据,而且栈帧的大小是提前计算好的,JVM 并不要求栈帧在内存地址是连续的。
HotSpot
JVM 中的 HotSpot 将字节码翻译成机器码有两种方法:
- 解释执行:逐条翻译字节码,逐条执行,无需等待编译,直接执行;
- 即时编译(Just-In-Time compilation,就是常说的 JIT):将一个方法中的字节码全部翻译完成后执行,需要等待编译,但实际运行速度更快;
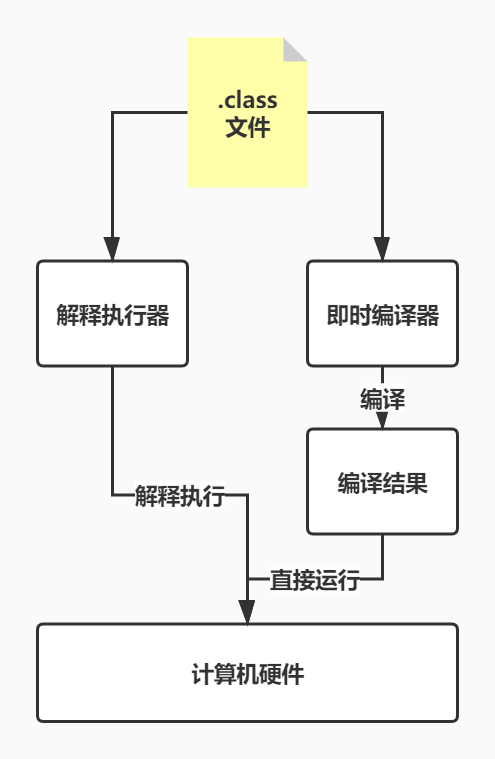
HotSpot 结合了两种方法,先执行字节码,对于反复调用的热点代码,以方法为单位进行即时编译。即时编译可以得到代码在运行时的信息,且可以根据这个信息做出相应的优化,在一定程度上是有可能超过 C++ 的速度的。
HotSpot 内置了多个即时编译器:
- C1:也叫 Client 编译器,面向的是对启动性能有要求的 GUI 程序,优化手段简单,编译时间短;
- C2:也叫 Server 编译器,面向的是峰值性能有较高要求的服务器端程序,优化手段复杂,编译时间长,但生成的字节码执行效率高;
Java7 后 HotSpot 采用混合编译,先使用 C1 对热点方法进行编译,对于后热点方法会进一步被 C2 编译。
即时编译为了不影响应用的正常运行,是放在额外的编译线程中运行的(CPU数量 * 线程数 = 可利用资源,极限情况下:可利用资源 - 1 = 编译线程),按照 1:2 分配给 C1 和 C2。资源充足的情况下,解释执行和即时编译同步进行,编译完成后,在下一次调用相同的方法时,会用即时编译的结果替换解释执行。
收集到的问题
-
为什么不把java代码全部编译成机器码?很多服务端应用发布频率不会太频繁,但是对运行时的性能和吞吐量要求较高。如果发布或启动时多花点时间编译,能够带来运行时的持久性能收益,不是很合适么?
答:因为对于发布不频繁的应用,使用线下编译和即时编译差别并不大,在经过一段时间后,也会对所有代码编译完成,而且即时编译会收集运行过程中的信息,对于优化有一定的帮助,换句话说,即时编译后能达到的峰值性能更高