Elasticsearch 读写操作原理整理
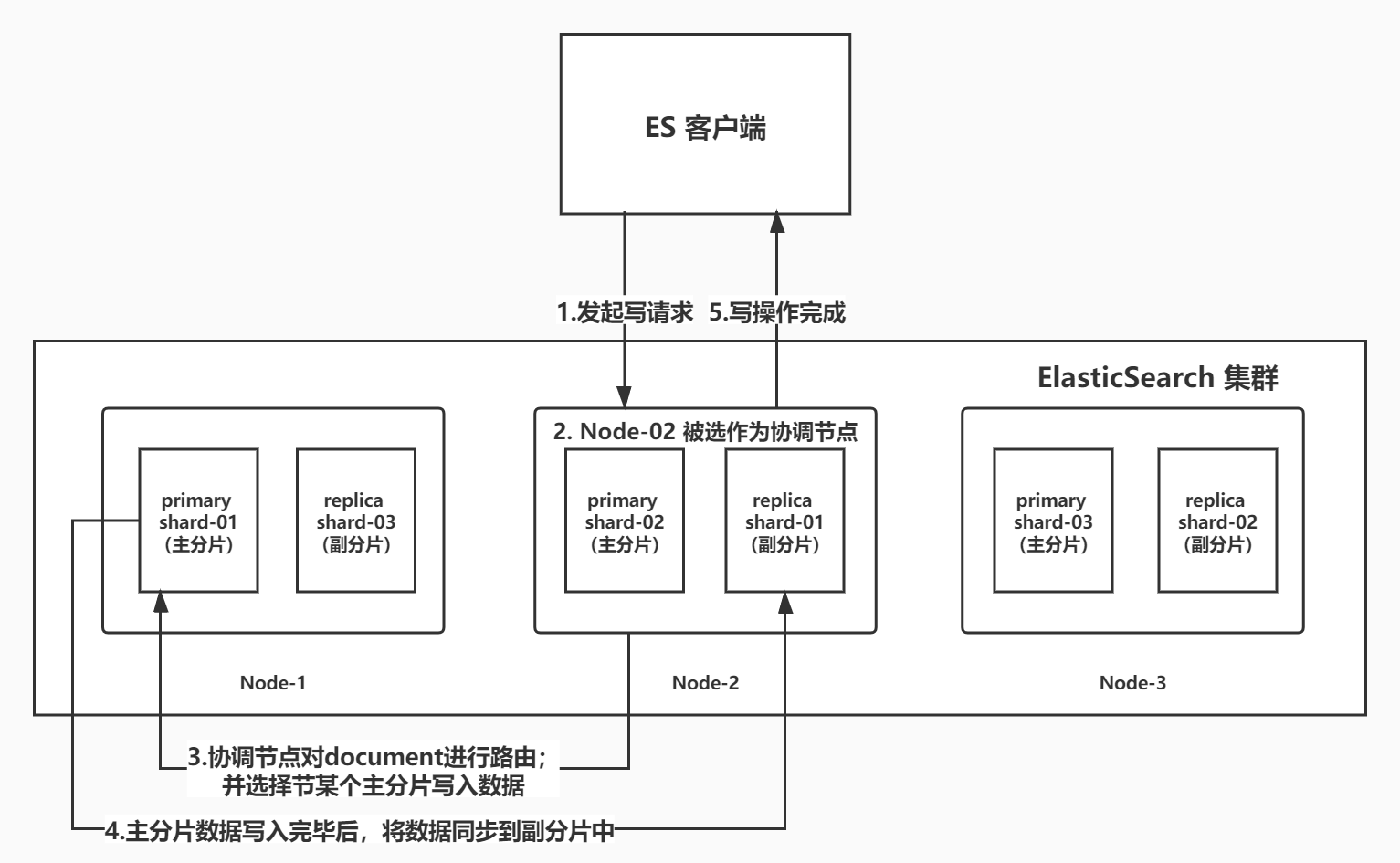
写数据主要流程
- Es 客户端选择集群中的一个节点发起写请求;
- Es 集群将节点标记为协调节点;
- 协调节点对写入的 document 进行路由,选择 primary shard 写入数据(图中只是表示简单路由到一个节点,实际会把数据路由到多个节点);
- 该 primary shard 上的数据写入完毕后,将数据同步到副分片中;
- 协调节点告诉客户端 primary shard 和 replica shard 已经写入数据完毕;
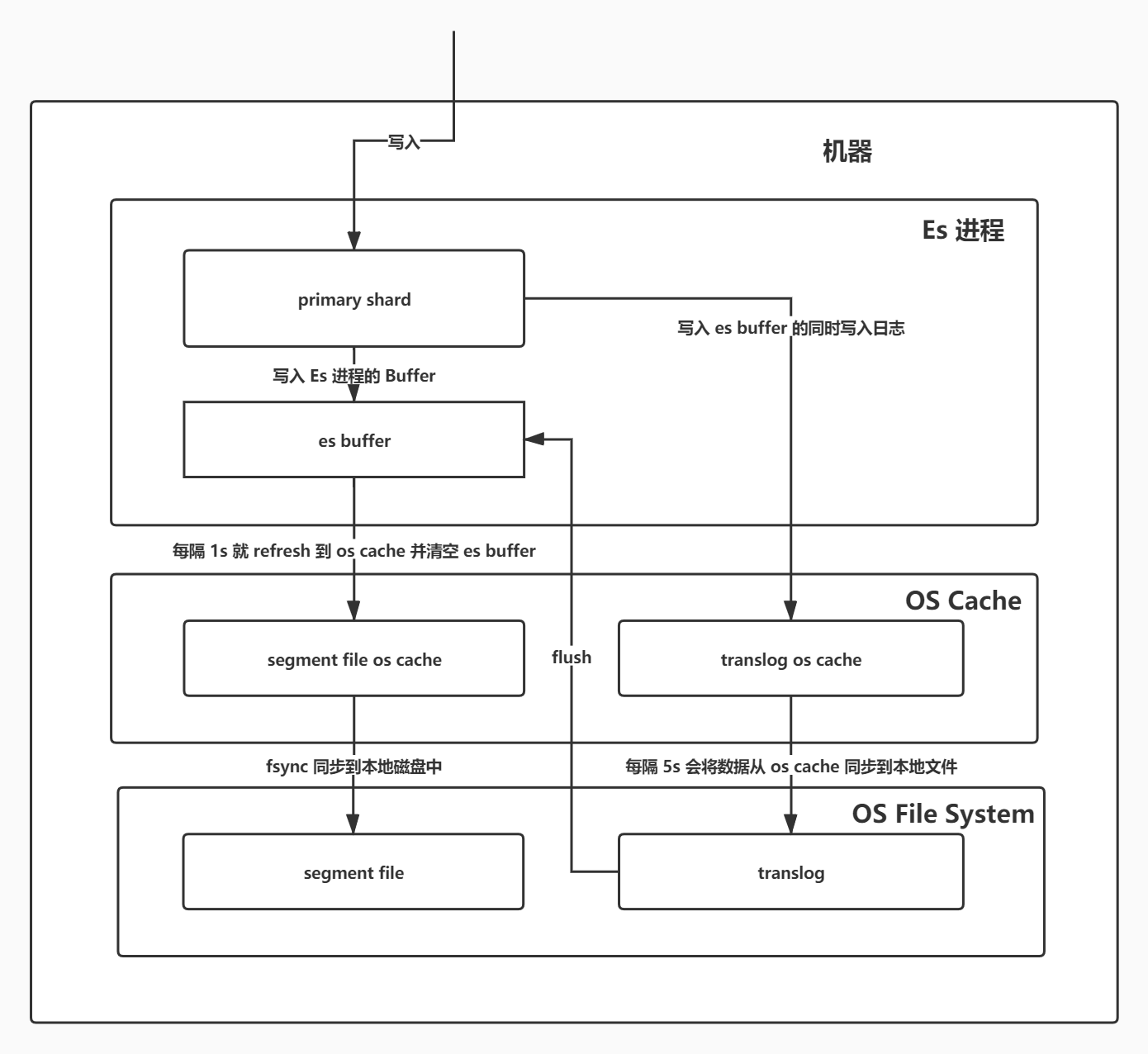
写数据详细流程(包含删除数据)
- 写入请求将数据同时发送到 Es 的 Buffer 缓存和 translog 日志,此时数据在 Es 进程的 Buffer 缓存中,无法查询到;
- 每隔 1 秒,Es Buffer 中的数据会被 Refresh 到
segment file os cache中,并清空 Es 进程的 Buffer 缓存,此时数据就可以被查到了(可以通过 API 触发); - 不断执行以上两部操作,segment file 会越来越多,Es 会定期将相似的
segment file合并,并将 .del 文件中标记的数据 删除(真正意义上的物理删除,而 .del 文件由commit point维护),然后将新的segment file写入磁盘; - 当 translog 太大,或者到达设置的默认时长(30min)后,就会触发一个
commit操作,这种操作也叫flush(可以通过 API 触发):- 先强行将 Es Buffer 中的数据写入
segment file os cache中,然后清空 Es Buffer; - 向磁盘写入一个
commit point文件,该文件标识着commit point对应的所有segment file; - 强行将
segment file os cache中的数据都 fsync 到磁盘文件中去; - 清空
translog文件,重启一个translog文件;
- 先强行将 Es Buffer 中的数据写入
translog 文件: 在执行 commit(flush)操作前,所有数据基本都是在 os cache 中的,一旦机器宕机,或者断电,内存中的数据就会全部丢失。所以将数据先写入一个专门的日志文件,当机器出现故障并重启后,可以从日志文件中将数据重新读取出来,恢复到 Es Buffer 和 os cahce 中,保证数据完整性。但是 translog 也是先写入到 translog os cache 中的,每经过 5 秒才会同步到本地磁盘,也就是说断电后,translog os cache 中的数也会丢失,但也是只丢失 5 秒的数据,但是性能要好一些;也可以设置为不写入 translog os cache 中,直接 fsync 到本地磁盘,但是这样性能会差一些;
segment file 文件: 存储逆向索引的文件,每个 segment file 本质上就是一个逆向索引;
commit point 文件: 这个文件中记录中所有可用的 segment file,并且每个 commit point 都会维护一个 .del 文件,当 Es 做删除时,并非物理删除,而是在 .del 文件中对要删除的数据进行记录,声明该 document 已经被删除,其实 Es 搜索数据的时候,还是可以从 segment file 中搜索出来的,但是当返回数据给客户端的时候,会根据 commit point 文件对声明删除的数据进行过滤;
读数据主要流程
- Es 客户端选择集群中的一个节点发起读请求;
- Es 集群将节点标记为协调节点;
- 根据 document id 进行路由,找到对应的 node 并将请求转发过去;
- 使用轮训算法在 primary shard 和 replica shard 中随机选择一个读取数据(负载均衡),然后将读取到的数据返回给协调节点;
- 协调节点将读取到的数据发给 Es 客户端;
流程图可参考写数据流程图;
搜索数据主要流程
- Es 客户端选择集群中的一个节点发起搜索请求;
- Es 集群将节点标记为协调节点;
- 协调节点将搜索请求发到所有的 shard 上;
- 每个 shard 自行搜索结果,并将搜索到的 document id 发给协调节点;
- 协调节点对 document id 进行去重,排序,分页等操作,然后再根据 document id 去各个 shard 上拉取实际的数据;(这一步实际上就是读数据过程)
- 最后将搜索到的数据返回给 Es 客户端;
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Tianyi's Blog!
评论