HDFS-读写操作原理整理
简介
设计思想
分而治之:将大文件大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析
重点概念
文件切块、副本存放、元数据
重要特性
-
HDFS 中的文件在物理上是分块存储,块的大小可以通过配置参数 dfs.blocksize 来规定,默认大小在 hadoop2.x 版本中是 128M
-
HDFS 文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件
-
目录结构及文件分块信息(元数据)的管理由 namenode 节点承担
namenode 是 HDFS 集群主节点,负责维护整个 HDFS 文件系统的目录树,以及每一个路径(文件)所对应的 block 块信息(block 的 id,及所在的 datanode 服务器)
-
文件的各个 block 的存储管理由 datanode 节点承担
datanode 是 HDFS 集群从节点,每个 block 都可以在多个 datanode 上存储多个副本(可以通过 dfs.replication 设置)
-
HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改
HDFS 角色说明
| 名称 | 作用 |
|---|---|
| namenode | 接受客户端的读写请求 存储元数据信息 接收 datanode 心跳报告 负载均衡 分配数据块的存储节点 |
| datanode | 真正处理客户端的读写请求 向 namenode 发送心跳 向 namenode 发送块报告 真正存储数据 副本之间的相互复制 |
| journalnode | 两个 namenode 为了数据同步,会通过一组称作 journalnode 的独立进程相互通信 当 active 状态的 namenode 的命名空间有任何修改时,会告知大部分的 journalnode 进程 |
| 客户端 | 进行数据块的物理切分 向 namenode 发送读写请求 向 namenode发送读写响应 |
HDFS 高可用机制
HDFS的高可用机制详解(journalnode 及 editlog)
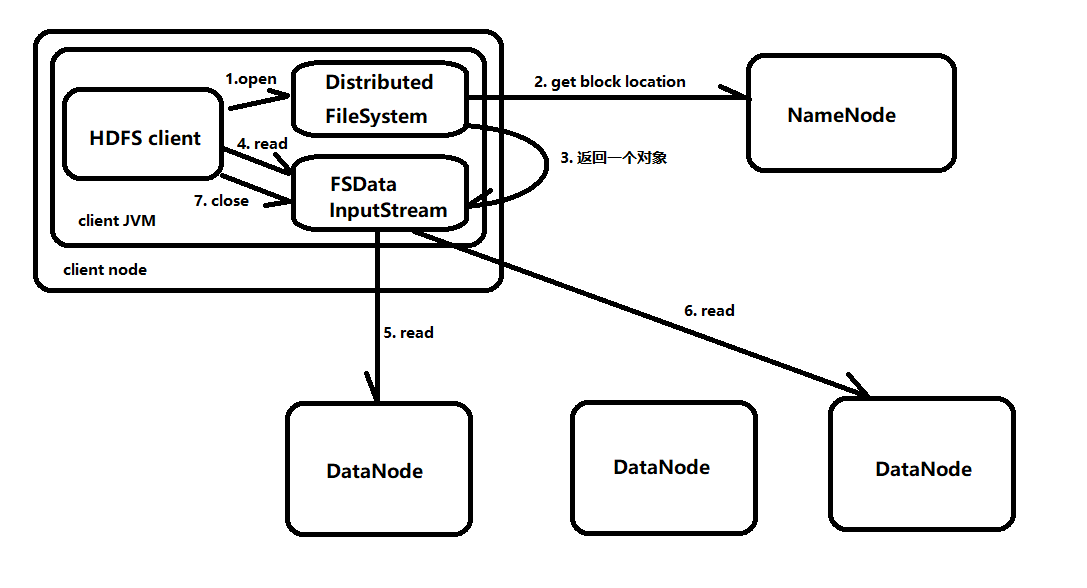
读数据流程
-
客户端通过调用 FileSyste 对象 DistributedFileSystem(以下简称 DFS) 的 open() 方法带打开希望读取的文件
-
DFS 对象通过远程调用(RPC)来调用 namenode,以确定文件起始块的位置
namenode 返回存储该数据块副本的 datanod 的地址,datanode 也会根据与客户端的距离来排序(就近原则读取信息)
-
DFS 类返回一个 FSDataInputStream 对象给客户端用于读取数据,FSDataInputStream 封装 DFSInputStream 对象,该对象管理 datanode 和 namenode 的 I/O
-
客户端调用 read() 方法
-
DFSInputStream 连接地址最近的一个 datanode,然后反复调用 read() 方法,将数据从 datanode 中传输到客户端。
-
读到块末端后,DFSInputStream 关闭连接,并开始寻找下一个最佳的 datanode,执行 4-5-6 步直至读取完成
-
读取完成后,就调用 close() 方法关闭 FSDataInputStream
写数据流程
-
客户端对 DistributedFileSystem(以下简称 DFS) 对象调用 create() 方法
-
DFS 对 namenode 创建一个 RPC 调用,在文件系统命名空间中创建一个文件,但没有对应的数据块
namenode 检查文件系统中是否存在这个文件,若不存在且客户端有权限创建,则创建一条记录,反之抛出异常
DFS 向客户端返回一个 FSDataOutputStream 对象,FSDataOutputStream 封装了 DFSOutputStream 对象
-
客户端调用 write 写数据
-
DFSOutputStream 将客户端的数据分包写入内部队列,称为 "数据队列"
队列的作用是选择一组合适的 datanode,要求 namenode 分配新的数据块,按照顺序发送数据到 datanode 中
-
DFSOutputStream 同时维护着一个 “确认队列”,所有 datanode 确认信息后,数据包才会从确认队列中删除
-
客户端完成数据写入后调用 close() 方法
-
联系 namenode 写入完成,等待确认