Zookeeper 概念笔记整理
简介
分布式协调服务,为其他的分布式程序提供协调服务
本身就是分布式程序
提供的服务包含:
- 主从协调
- 服务器节点动态上下线
- 统一配置管理
- 分布式共享锁
- 统一名称服务
底层其实只包含两层服务
- 管理(存储和读取)用户程序提交的数据
- 为用户程序提供数据节点监听服务
特性
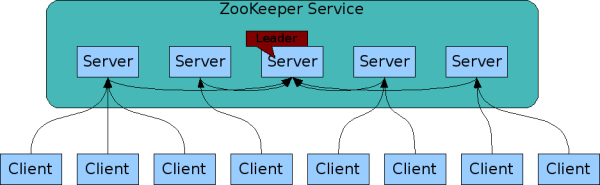
- 一个 leader,多个 follower 组成的集群
- 全局数据一致:每个 ZK 服务器的数据都是一致的,无论哪个客户端连接到 ZK,获得的数据都是一样的
- 分布式读写:更新请求转发,由 leader 实施
- 顺序执行:来自同一个客户的更新请求按照发送顺序执行
- 数据更新原子性:要么成功,要么失败
- 实时性:在一定时间范围内,客户端能得到最新的数据
数据结构
- 层次化结构,和文件系统差不多
- 每个节点叫做 znode,并且有唯一路径标识
- 每个 znode 可以包含数据和子节点(EPHEMERAL 不能有子节点,因为是短暂节点,连接断开后会自己删除)
- 客户端可以在节点上设置监视器
Znode 节点类型
- 有两种节点类型
- 短暂(EPHEMERAL)断开连接自己删除
- 持久(PERSISTENT)断开连接不删除
- org.apache.zookeeper.CreateMode中定义了四种节点类型
- PERSISTENT:永久节点
- EPHEMERAL:临时节点
- PERSISTENT_SEQUENTIAL:永久节点、序列化
- EPHEMERAL_SEQUENTIAL:临时节点、序列化
- 创建 znode 是设置顺序表示,znode 名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护,设置顺序是为了对所有事件进行全局排序,客户端就可以通过顺序推断事件的顺序
分布式共享锁
**作用:**做到一次只有指定个数的客户端访问服务器的某些资源
实现步骤:
- 客户端上线就向 ZK 注册,创建一把锁
- 判断是否只有一个客户端在工作,是则该客户端处理业务
- 获取父节点下注册的所有锁,判断自己是否是注册号码最小的,是则处理业务
当业务处理完成后必须要释放锁
ZooKeeper 中的时间
-
Zxid
致使 ZooKeeper 节点状态改变的每一个操作都将使节点接收到一个 zxid 格式的时间戳,并且这个时间戳全局有序。
- cZxid:是节点的创建时间所对应的 Zxid 格式时间戳。
- mZxid:是节点的修改时间所对应的 Zxid 格式时间戳,与其子节点无关。
- pZxid:该节点的子节点(或该节点)的最近一次 创建 / 删除 的修改时间所对应的 cZxid 格式时间戳(注:只与 本节点 / 该节点的子节点,有关;与孙子节点无关
-
版本号
对节点的每一个操作都将致使这个节点的版本号增加。每个节点维护着三个版本号,他们分别为:
- version 节点数据版本号
- cversion 子节点版本号
- aversion 节点所拥有的 ACL 版本号
Zookeeper 投票机制
用例子比较直观(配置 3 台机器):
每台机器的 “票” 结构:(myid,zxid)
-
情况一
T1(1,0) T2(2,0) T3(3,0)
T1 启动给自己投一票
T2 启动给自己投一票,收到 T1 的票,并将自己的票发给 T1
—— 判断(如果 zxid 相同,则 myid 大的作为 leader)T2 作为 leader
T3 启动已经有 leader 了,不再参与选举直接指定 T2 作为leader
-
情况二
T1 (1,3) T2(2,10) T3(3,5)
T2 作为 leader 然后嗝屁了
T1 和 T3 选举
—— 判断(如果 zxid 不同,则直接判断 zxid,和 myid 无关)T3 作为 leader
T2 重新上线后由于 T3 已经是 leader,直接指定 T3 为 leader
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Tianyi's Blog!
评论